 Azərbaycanca
Azərbaycanca Беларускі
Беларускі Dansk
Dansk Deutsch
Deutsch Española
Española Français
Français Indonesia
Indonesia Italiana
Italiana 日本語
日本語 Қазақ
Қазақ Lietuvos
Lietuvos Nederlands
Nederlands Português
Português Русский
Русский සිංහල
සිංහල แบบไทย
แบบไทย Türkçe
Türkçe Українська
Українська 中國人
中國人 United State
United State Afrikaans
Afrikaans
İstatistik bilim dalı içinde Friedman sıralamalı iki yönlü varyans analizi sonradan çok tanınmış bir iktisatçı olan Amerikan Milton Friedman tarafından ortaya atılan bir parametrik olmayan istatistik .
Bu sınama için veriler k sayıda birbirine eşlenen örneklem halindedir. Örneğin aynı örneklem elemanları k değişik koşullar altında ölçülebilir veya k tane eleman bulup bunları değişik koşullar altına rastgele dağıtarak ölçümler yapmak suretiyle olabilir. Bu çeşit için benzer parametrik sınama varyans analizi adını taşır; Ayni zamanda adlı deneysel tasarım verileri için kullanılan parametrik benzer.
Bu sınamanın kullanılmış olduğu bilinen klasik pratik problemler arasında şunlar bulunur:
- n sayıda şarap ekperi k sayıda değişik şarabı tadım yapmak suretiyle değerlendirmektedirler. Değişik ekperlerin değerlendirmeleri birbirlerine uygun mudur?
- n sayıda kaynakçı k sayıda değişik kaynak makinesi kullanmaktadırlar ve yaptıkları kaynaklar merkezi kalite kontrolü tarafından tekrar kontrol edilmektedir. Diğerlerinden daha iyi kaynaklar ortaya çıkartan özel bir kaynak makinası bulunmakta mıdır?
Friedman sınaması için örneklem verisi n satırlı k sütunlu bir veri tablosu halindedir. Her bir satır bir elemanı veya hali veya bloku ve her bir sütun da bu satır nesnelerinin tabi oldukları değişik koşulları gösterir. Ancak analiz yapmak için bu veriler değiştirilip yeni bir tablo kurulur. Bu her bir satır için sıralama düzeni uygulanması suretiyle başarılır; yani her bir satır elemanının sütunları 1,....,k arasında bir sıra numarası verilerek sıralanır. Friedman sınamasının amacı, her değişik koşul için sıralama düzeninin tek bir anakütleden mi geldiğini yoksa ayrı anakütlelerden mi geldiğini incelemektir. Bu sınamayı sağlamak için her sütun için sıralama numaraları toplamlarının birbirine benzer mi yoksa birbirinden çok değişik mi olduğu incelenir.
Friedman sınaması sıralama düzeni kullanılması nedeniyle Kruskal-Wallis sıralamalı tek yönlü varyans analizi hesaplarına da benzemektedir..
Yöntem
- Birbirlerine eşli olan n sayıda eleman veya hal için k değişken hakkında sayısal veri toplanır. Birbirine eşli olduğu için bu verilerin bulunması için özel deneysel tasarım uygulanması gerekmektedir. Bu şeklinde olduğu için varyans analizi terimleri ile satırlara blok ismi verilir. Böylece n satırlı k sütunlu (bir matris şeklinde) bir veri tablosu elde edilir ve bu veri tablosunda da her bir hücrede tek bir sayısal ölçüm
![image]() bulunur. Bu i blokunun tabi olduğu j koşuldan ortaya çıkan niceliksel ölçekli sayısal bir ölçümdür ve bütün veri ölçümleri aynı birimlerdedir.
bulunur. Bu i blokunun tabi olduğu j koşuldan ortaya çıkan niceliksel ölçekli sayısal bir ölçümdür ve bütün veri ölçümleri aynı birimlerdedir. - Sınamanın amacı anakütlenin k sayıda koşula göre bölünmesinin etkili olup olmadığıdır. Eğer k sayıdakı koşul anakütlenin k bölüme ayrılmasına neden olursa eldeki örneklemde her koşula ait sıralamalar toplamı birbirinden değişik toplam verecektir. Eğer koşul değişmesi anakütle bölünmesine neden olmuyorsa, örneklem için her bir sütun birbirine eşit sıralama toplamı verecektir. Buna göre Friedman sınaması için sıfır hipotez ve karşıt hipotez şöyle verilir: H0 : k koşul etkilerinin tümü birbirine aynıdır yani koşul değişikliği anakütlenin bölünmesini sağlamaz. H1 : k koşullardan bazılarının etkileri birbirine eşittir ve diğerleri eşit olmayıp anakütlenin bölünmesini sağlarlar.
- İlk yapılan hesaplar ile yeni bir veri tablosu elde edilir. Bu yeni tabloda n sayıda blok veya eleman satırı ve k sayıda da koşul sütunu bulunur. Her bir blok için koşullar sıralama düzenine konulmuştur yani yeni veri tablosunda her satırdaki veriler '1' den 'k'ye kadar sıra numarasıdır. Eğer ilk veri matrisinde bir blok satırı içinde beraberlikler bulunursa kullanılacak sıralama stratejisi beraberliklerin sıralama ortalamasının her beraberlik için kullanmasıdır; bu halde kesirler sıralama numaraları bulunabilir . Bu yeni tablodaki her eleman i=1,..,k ve j=1,...n için
![image]() sıra numaraları olur.
sıra numaraları olur. - Bu yeni veri tablosu kullanılarak şu ortalama ve toplam kare değerleri bulunur:
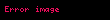
![image]() (Sütun ortalaması)
(Sütun ortalaması)![image]() (Toplam ortalaması)
(Toplam ortalaması)![image]() (Toplam toplam-kare);
(Toplam toplam-kare);![image]() (Hatalar toplam kare)
(Hatalar toplam kare)




- Toplam kare hesapları kullanılarak sınama istatistiği şu ifade olarak bulunur:

Burada dikkate değer bir nokta bu formüle göre hesaplanan Q istatistiğini verilerin sıralama düzenine koyuldukları zaman bulunan beraberlikler için hiç düzeltme istemediğidir.
- En son aşamada sıfır hipotez hakkında sonuç çıkartılır:
- Eğer n veya k büyükse (yani n>15 veya k>4 ise), Q için olasılık dağılımı yaklaşık olarak (k-1) serbestlik dereceli bir ki-kare dağılımı gösterir. Bu halde p-değeri
![image]() ile bulunur. Bulunan p-değeri anlamlılık düzeyi yüzdeleri (%5 veya %1) ile karşılaştırılır. Eğer p-değeri daha küçükse sıfır hipotez reddedilir.
ile bulunur. Bulunan p-değeri anlamlılık düzeyi yüzdeleri (%5 veya %1) ile karşılaştırılır. Eğer p-değeri daha küçükse sıfır hipotez reddedilir. - Eğer n veya k küçükse (yani n=<15 veya k=<4 ise), Friedman sınaması için hazırlanmış Q tabloları kullanılıp %5 veya %1 anlamlılık düzeyi değerleri bulunup bu tablo değerleri hesaplanmış Q değeri ile karşılaştırılır. Eğer hesaplanmış Q değeri daha büyükse sıfır hipotez reddedilir.
- Eğer sınama sonucu olarak sıfır hipotez reddedilirse, problem sonucu kesin değildir ve kesin hangi koşulların birlikte etki yaptıklarını incelemek için (post-hoc analiz) sınamaları kullanmak gereklidir.

İlişkili sınamalar
Eğer bu türlü deneysel tasarım iki kategorili veri ortaya çıkartırsa, kullanılması gereklidir.
Kaynakça
- ^ Friedman, Milton (1937) "The use of ranks to avoid the assumption of normality implicit in the analysis of variance", Journal of the American Statistical Association C.32 No.200 say.675–701 [1]
- ^ Friedman, Milton (1939) "A correction: The use of ranks to avoid the assumption of normality implicit in the analysis of variance" Journal of the American Statistical Association C.34 No.109 say.109 [2]
- ^ Friedman, Milton (1940) "A comparison of alternative tests of significance for the problem of m rankings", The Annals of Mathematical Statistics C.11 No.1 say.86–92 [3]
Dışsal kaynaklar
- Texasoft istatistik dersnotlari 17 Mayıs 2008 tarihinde Wayback Machine sitesinde .
- Kendall, M.G. (1970), Rank Correlation Methods 4ncu ed., Londra: Charles Griffin.
- Hollander,M. ve Wolfe,D.A. (1973), Nonparametric Statistics, New York: J. Wiley.
- Siegel,Sidney ve Castellan,N.John Jr. (1988), Nonparametric Statistics for the Behavioral Sciences. 2. ed.) New York: McGraw-Hill.
wikipedia, wiki, viki, vikipedia, oku, kitap, kütüphane, kütübhane, ara, ara bul, bul, herşey, ne arasanız burada,hikayeler, makale, kitaplar, öğren, wiki, bilgi, tarih, yukle, izle, telefon için, turk, türk, türkçe, turkce, nasıl yapılır, ne demek, nasıl, yapmak, yapılır, indir, ücretsiz, ücretsiz indir, bedava, bedava indir, mp3, video, mp4, 3gp, jpg, jpeg, gif, png, resim, müzik, şarkı, film, film, oyun, oyunlar, mobil, cep telefonu, telefon, android, ios, apple, samsung, iphone, xiomi, xiaomi, redmi, honor, oppo, nokia, sonya, mi, pc, web, computer, bilgisayar
Istatistik bilim dali icinde Friedman siralamali iki yonlu varyans analizi sonradan cok taninmis bir iktisatci olan Amerikan Milton Friedman tarafindan ortaya atilan bir parametrik olmayan istatistik Bu sinama icin veriler k sayida birbirine eslenen orneklem halindedir Ornegin ayni orneklem elemanlari k degisik kosullar altinda olculebilir veya k tane eleman bulup bunlari degisik kosullar altina rastgele dagitarak olcumler yapmak suretiyle olabilir Bu cesit icin benzer parametrik sinama varyans analizi adini tasir Ayni zamanda adli deneysel tasarim verileri icin kullanilan parametrik benzer Bu sinamanin kullanilmis oldugu bilinen klasik pratik problemler arasinda sunlar bulunur n sayida sarap ekperi k sayida degisik sarabi tadim yapmak suretiyle degerlendirmektedirler Degisik ekperlerin degerlendirmeleri birbirlerine uygun mudur n sayida kaynakci k sayida degisik kaynak makinesi kullanmaktadirlar ve yaptiklari kaynaklar merkezi kalite kontrolu tarafindan tekrar kontrol edilmektedir Digerlerinden daha iyi kaynaklar ortaya cikartan ozel bir kaynak makinasi bulunmakta midir Friedman sinamasi icin orneklem verisi n satirli k sutunlu bir veri tablosu halindedir Her bir satir bir elemani veya hali veya bloku ve her bir sutun da bu satir nesnelerinin tabi olduklari degisik kosullari gosterir Ancak analiz yapmak icin bu veriler degistirilip yeni bir tablo kurulur Bu her bir satir icin siralama duzeni uygulanmasi suretiyle basarilir yani her bir satir elemaninin sutunlari 1 k arasinda bir sira numarasi verilerek siralanir Friedman sinamasinin amaci her degisik kosul icin siralama duzeninin tek bir anakutleden mi geldigini yoksa ayri anakutlelerden mi geldigini incelemektir Bu sinamayi saglamak icin her sutun icin siralama numaralari toplamlarinin birbirine benzer mi yoksa birbirinden cok degisik mi oldugu incelenir Friedman sinamasi siralama duzeni kullanilmasi nedeniyle Kruskal Wallis siralamali tek yonlu varyans analizi hesaplarina da benzemektedir YontemBirbirlerine esli olan n sayida eleman veya hal icin k degisken hakkinda sayisal veri toplanir Birbirine esli oldugu icin bu verilerin bulunmasi icin ozel deneysel tasarim uygulanmasi gerekmektedir Bu seklinde oldugu icin varyans analizi terimleri ile satirlara blok ismi verilir Boylece n satirli k sutunlu bir matris seklinde bir veri tablosu elde edilir ve bu veri tablosunda da her bir hucrede tek bir sayisal olcum xij displaystyle x ij bulunur Bu i blokunun tabi oldugu j kosuldan ortaya cikan niceliksel olcekli sayisal bir olcumdur ve butun veri olcumleri ayni birimlerdedir Sinamanin amaci anakutlenin k sayida kosula gore bolunmesinin etkili olup olmadigidir Eger k sayidaki kosul anakutlenin k bolume ayrilmasina neden olursa eldeki orneklemde her kosula ait siralamalar toplami birbirinden degisik toplam verecektir Eger kosul degismesi anakutle bolunmesine neden olmuyorsa orneklem icin her bir sutun birbirine esit siralama toplami verecektir Buna gore Friedman sinamasi icin sifir hipotez ve karsit hipotez soyle verilir H0 k kosul etkilerinin tumu birbirine aynidir yani kosul degisikligi anakutlenin bolunmesini saglamaz H1 k kosullardan bazilarinin etkileri birbirine esittir ve digerleri esit olmayip anakutlenin bolunmesini saglarlar Ilk yapilan hesaplar ile yeni bir veri tablosu elde edilir Bu yeni tabloda n sayida blok veya eleman satiri ve k sayida da kosul sutunu bulunur Her bir blok icin kosullar siralama duzenine konulmustur yani yeni veri tablosunda her satirdaki veriler 1 den k ye kadar sira numarasidir Eger ilk veri matrisinde bir blok satiri icinde beraberlikler bulunursa kullanilacak siralama stratejisi beraberliklerin siralama ortalamasinin her beraberlik icin kullanmasidir bu halde kesirler siralama numaralari bulunabilir Bu yeni tablodaki her eleman i 1 k ve j 1 n icin rij displaystyle r ij sira numaralari olur Bu yeni veri tablosu kullanilarak su ortalama ve toplam kare degerleri bulunur r j 1n i 1nrij displaystyle bar r cdot j frac 1 n sum i 1 n r ij Sutun ortalamasi r 1nk i 1n j 1krij displaystyle bar r frac 1 nk sum i 1 n sum j 1 k r ij Toplam ortalamasi SSt n j 1k r j r 2 displaystyle SS t n sum j 1 k bar r cdot j bar r 2 Toplam toplam kare SSe 1n k 1 i 1n j 1k rij r 2 displaystyle SS e frac 1 n k 1 sum i 1 n sum j 1 k r ij bar r 2 Hatalar toplam kare Toplam kare hesaplari kullanilarak sinama istatistigi su ifade olarak bulunur Q SStSSe displaystyle Q frac SS t SS e Burada dikkate deger bir nokta bu formule gore hesaplanan Q istatistigini verilerin siralama duzenine koyulduklari zaman bulunan beraberlikler icin hic duzeltme istemedigidir En son asamada sifir hipotez hakkinda sonuc cikartilir Eger n veya k buyukse yani n gt 15 veya k gt 4 ise Q icin olasilik dagilimi yaklasik olarak k 1 serbestlik dereceli bir ki kare dagilimi gosterir Bu halde p degeri P xk 12 Q displaystyle mathbf P chi k 1 2 geq Q ile bulunur Bulunan p degeri anlamlilik duzeyi yuzdeleri 5 veya 1 ile karsilastirilir Eger p degeri daha kucukse sifir hipotez reddedilir Eger n veya k kucukse yani n lt 15 veya k lt 4 ise Friedman sinamasi icin hazirlanmis Q tablolari kullanilip 5 veya 1 anlamlilik duzeyi degerleri bulunup bu tablo degerleri hesaplanmis Q degeri ile karsilastirilir Eger hesaplanmis Q degeri daha buyukse sifir hipotez reddedilir Eger sinama sonucu olarak sifir hipotez reddedilirse problem sonucu kesin degildir ve kesin hangi kosullarin birlikte etki yaptiklarini incelemek icin post hoc analiz sinamalari kullanmak gereklidir Iliskili sinamalarEger bu turlu deneysel tasarim iki kategorili veri ortaya cikartirsa kullanilmasi gereklidir Kaynakca Friedman Milton 1937 The use of ranks to avoid the assumption of normality implicit in the analysis of variance Journal of the American Statistical Association C 32 No 200 say 675 701 1 Friedman Milton 1939 A correction The use of ranks to avoid the assumption of normality implicit in the analysis of variance Journal of the American Statistical Association C 34 No 109 say 109 2 Friedman Milton 1940 A comparison of alternative tests of significance for the problem of m rankings The Annals of Mathematical Statistics C 11 No 1 say 86 92 3 Dissal kaynaklarTexasoft istatistik dersnotlari 17 Mayis 2008 tarihinde Wayback Machine sitesinde Kendall M G 1970 Rank Correlation Methods 4ncu ed Londra Charles Griffin Hollander M ve Wolfe D A 1973 Nonparametric Statistics New York J Wiley Siegel Sidney ve Castellan N John Jr 1988 Nonparametric Statistics for the Behavioral Sciences 2 ed New York McGraw Hill